Why Legacy Bucket Unionization Breaks LSH-MinHash Dedup
A practical hypergraph fix for web-scale LSH-MinHash deduplication and query.
Most MinHash-LSH dedup pipelines still do this in stage 3:
- Build duplicate buckets from band collisions.
- Merge overlapping buckets transitively (bucket unionization).
- Keep one representative per merged component.
That is simple and often fast. In multi-band dedup, it is also the wrong objective.
This post explains why, shows the correct formulation, sketches the algorithm, and summarizes the empirical impact on billion-scale corpora.
Contents
- Why this matters for ML teams
- Formal thesis and violated invariant
- Pipeline context
- Pipeline diagram: hold vs break
- Where transitive bucket unionization fails
- Correct formulation
- Key theorems
- Algorithm sketch
- Complexity and memory
- Multi-seed extension
- Query-side extension
- Case studies
- Interactive exploration
- Migration checklist
- Limitations and future work
TL;DR
- In multi-band MinHash-LSH, bucket overlap is not a transitive duplicate relation.
- The right stage-3 objective is: keep a maximum set of documents such that every bucket contributes at most one retained document.
- This is a strong-independent-set problem on a bucket hypergraph.
- A bucket-native greedy algorithm plus weight-1 preprocessing yields strong practical behavior at scale.
- Multi-seed dedup sharpens acceptance and lowers low-similarity false positives while reusing the same pipeline workflow.
Formal thesis: what legacy unionization adds (and why invalid)
Let bucket evidence be represented by a deduplicated hyperedge family $\mathcal{B}$. The native LSH feasibility region is:
\[\mathcal{F}_{\mathrm{LSH}} := \{R \subseteq V : |R \cap B| \le 1,\ \forall B \in \mathcal{B}\}.\]Legacy bucket unionization first forms transitive overlap components and then enforces one representative per component; call that region $\mathcal{F}_{\mathrm{union}}$.
By construction,
\[\mathcal{F}_{\mathrm{union}} \subseteq \mathcal{F}_{\mathrm{LSH}},\]and the inclusion can be strict.
The key violated invariant is: LSH emits local collision evidence, not transitive global equivalence classes. Legacy unionization adds constraints not entailed by emitted buckets.
Why this matters for ML teams
Large language model training quality depends heavily on data curation quality. If clustering over-merges, we lose useful diversity and discard too many documents. If clustering under-merges, we leak near-duplicates and waste token budget. The importance of strong dedup signals for LLM training quality has been demonstrated repeatedly in practice and ablations.123
Many production pipelines have excellent stage-1/2 engineering (signatures + bucketing), but a stage-3 semantic mismatch: transitive bucket unionization in a setting where duplicate evidence is local-by-bucket, not globally transitive.
This is why we focus on stage 3 as a targeted, high-leverage change.
Pipeline context: what changes and what does not
We keep the standard 4-stage structure:
- Signature generation
- Bucketing
- Clustering
- Filtering
Only stage 3 changes.4
This is important operationally: no need to replace your hash family, bucketing framework, or filtering pipeline.
We keep the same MinHash-LSH candidate-generation foundations and only change clustering semantics.56
Pipeline diagram: where assumptions hold vs break

Where transitive bucket unionization fails in multi-band
3.1 Local clique vs global transitivity
Each bucket is a local duplicate clique by construction. But overlap between buckets does not imply transitive pairwise similarity.
You can have:
- $x, y$ together in one bucket
- $y, z$ together in another bucket
- $x, z$ sharing no bucket at all
Legacy transitive bucket unionization still merges $x, y, z$ and keeps one representative, which is stronger than the true feasibility requirement.
3.2 Worst-case gap can be unbounded
Build a chain of pair buckets:
\[B_i=\{x_i,y_i\},\quad E_i=\{y_i,x_{i+1}\},\quad i=1,\dots,k-1.\]Bucket-overlap graph is connected, so transitive-union retention is 1.
But ${x_1,\dots,x_k}$ is feasible under per-bucket uniqueness, so feasible retention is $k$.
So transitive-union retention can be $1/k$ of feasible optimum, tending to 0 as $k\to\infty$.
Correct formulation: bucket hypergraph + strong independence
Let:
- $V$: document set
- $\mathcal{B}$: deduplicated bucket family (identical buckets merged)
- $H=(V,\mathcal{B})$: hypergraph (bucket = hyperedge)
A retained set $R\subseteq V$ is feasible iff:
\[|R\cap B|\le 1\quad\forall B\in\mathcal{B}.\]The objective is:
\[\alpha(\mathcal{B})=\max\{|R|: R\subseteq V,\ |R\cap B|\le 1,\ \forall B\in\mathcal{B}\}.\]That is exactly maximum strong independent set in this hypergraph.7 In general, this optimization family is NP-hard, so the goal is not a universal exact solver at billion scale, but a formulation and algorithm that are both faithful and operationally tractable.8
Two key theorems (the practical ones)
Theorem A: Explicit upper bound from bucket incidences
Define:
-
document degree: $d(v)= {B\in\mathcal{B}:v\in B} $ - minimum bucket weight: $w(B)=\min_{v\in B}d(v)$
Then every feasible retained set satisfies:
\[|R|\le \sum_{B\in\mathcal{B}}\frac{1}{w(B)}.\]Intuition: each retained doc has one unit of budget spread across its incident buckets.
Low-$w(B)$ buckets are most constraining, hence good candidates to process first.
Theorem B: Weight-1 refinement
Buckets with $w(B)=1$ are structurally special: an optimal solution can be chosen to include a degree-1 representative from each such bucket. Removing those forced assignments and recomputing residual buckets gives a tighter practical upper bound than the raw sum above.
This refinement is key for meaningful empirical “closeness to bound” diagnostics. In other words: the tighter the bound, the more informative your “greedy vs bound” percentage becomes.
Algorithm sketch: Greedy minimum-bucket-weight clustering
Below is the implementation-oriented sketch (matching the paper logic):
Input: deduplicated bucket family B
Output: root set R, cluster map phi
1. Compute document degrees d(v), bucket weights w(B).
2. Weight-1 pre-elimination:
- For each bucket with w(B)=1:
pick a degree-1 root z_B, cluster current unassigned members to z_B.
3. Remove already-clustered docs from remaining buckets;
keep non-empty residual buckets B_res.
4. Recompute residual degrees d_res(v), initialize key degree d~(v)=d_res(v).
5. Build min-heap over residual buckets with key:
( min_{v in bucket} d~(v), bucket_id ).
6. While heap non-empty:
a) Pop lightest bucket.
b) Partition members into unresolved docs U and active roots A.
c) If A empty and U non-empty:
- if tightened weight now exceeds current level, requeue;
- else create root u* = argmin_{v in U}(d~(v), id(v)),
attach U to u*.
d) If |A|=1: attach U to that root.
e) If |A|>1: keep best root by (d~(v), id(v)),
merge others into it, attach U.
f) Update d~ and release processed bucket.
7. Return R and phi.
Invariant and guarantee
- Invariant: no bucket contains more than one active root at any step.
- Consequence: output root set is always feasible.
- Also: output is maximal feasible (no extra document can be added without violating a bucket constraint).
Complexity and memory behavior
Let:
\[I=\sum_{v\in V}d(v)=\sum_{B\in\mathcal{B}}|B|\]be total bucket-document incidence.
- Preprocessing + weight-1 elimination + residual degree recomputation: $O(I)$.
- Residual greedy stage:
where $J_{\text{res}}$ is residual incidence scanned over requeues, $K_{\text{res}}$ residual heap visits, and $M_{\text{res}}$ residual bucket count.
Practical memory profile is output-state dominated: beyond transient bucket/heap workspace, resident state is mainly root set $R$ and cluster map $\phi$. This is one reason the method remains practical for very large corpora.
Multi-seed dedup as a first-class extension
Run the same dedup pipeline for $T$ independent seeds and aggregate constraints.
If $p_{\text{sb}}(s)$ is per-band match probability at similarity $s$, then no-match over $Tb$ merged bands factorizes:
\[\Pr[\text{no match on all }Tb\text{ bands}] = (1-p_{\text{sb}}(s))^{Tb}.\]So merged-signature view and multi-round independent-seed view are probabilistically equivalent at candidate-generation level.
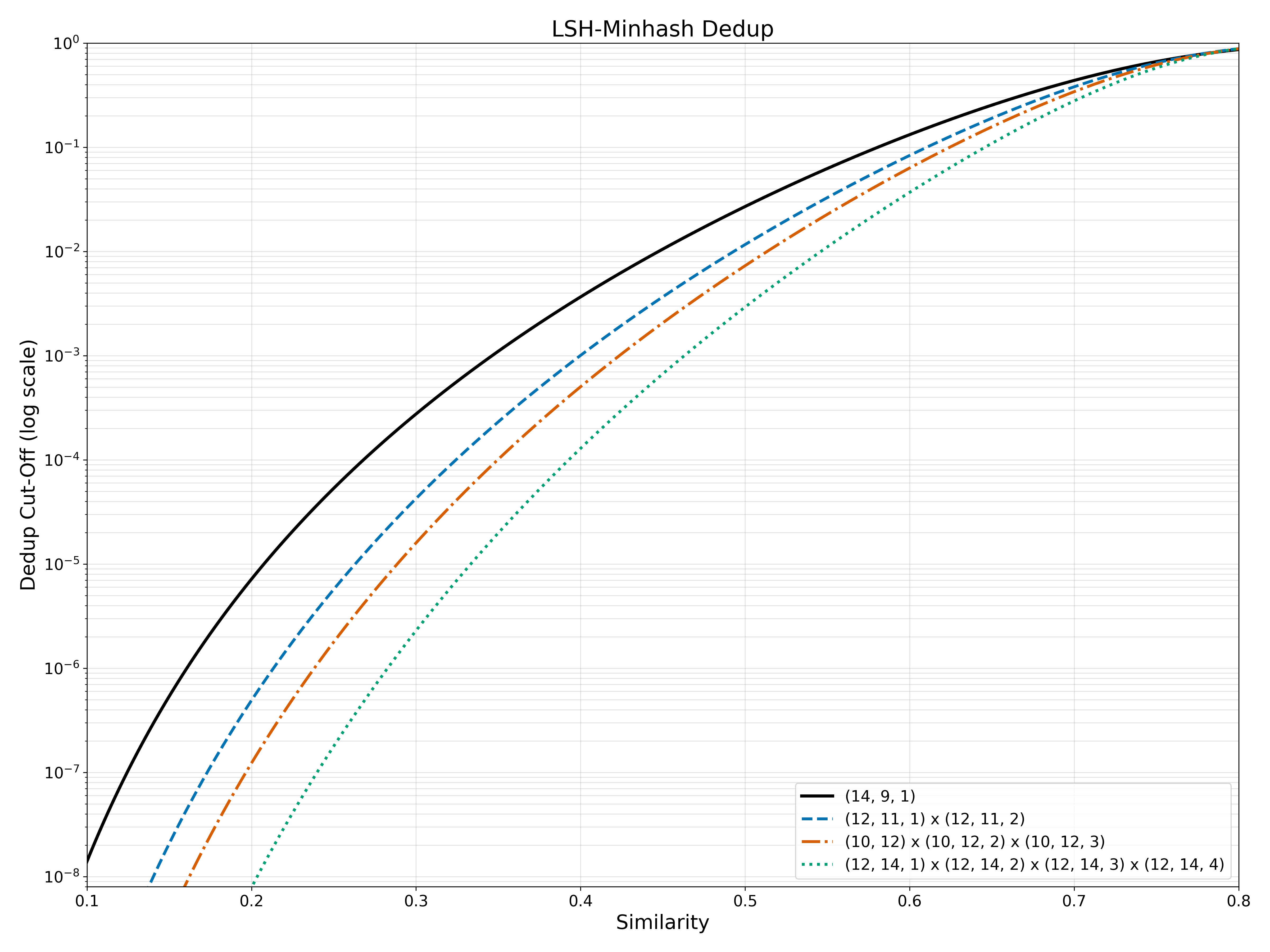
Why this is useful in practice: sharper transition near useful similarity region and much lower low-similarity tail false positives, without inventing a new clustering primitive. This is one of the highest-ROI changes because it reuses the same workflow with different seeds.
Figure: multi-seed acceptance curves (linear)
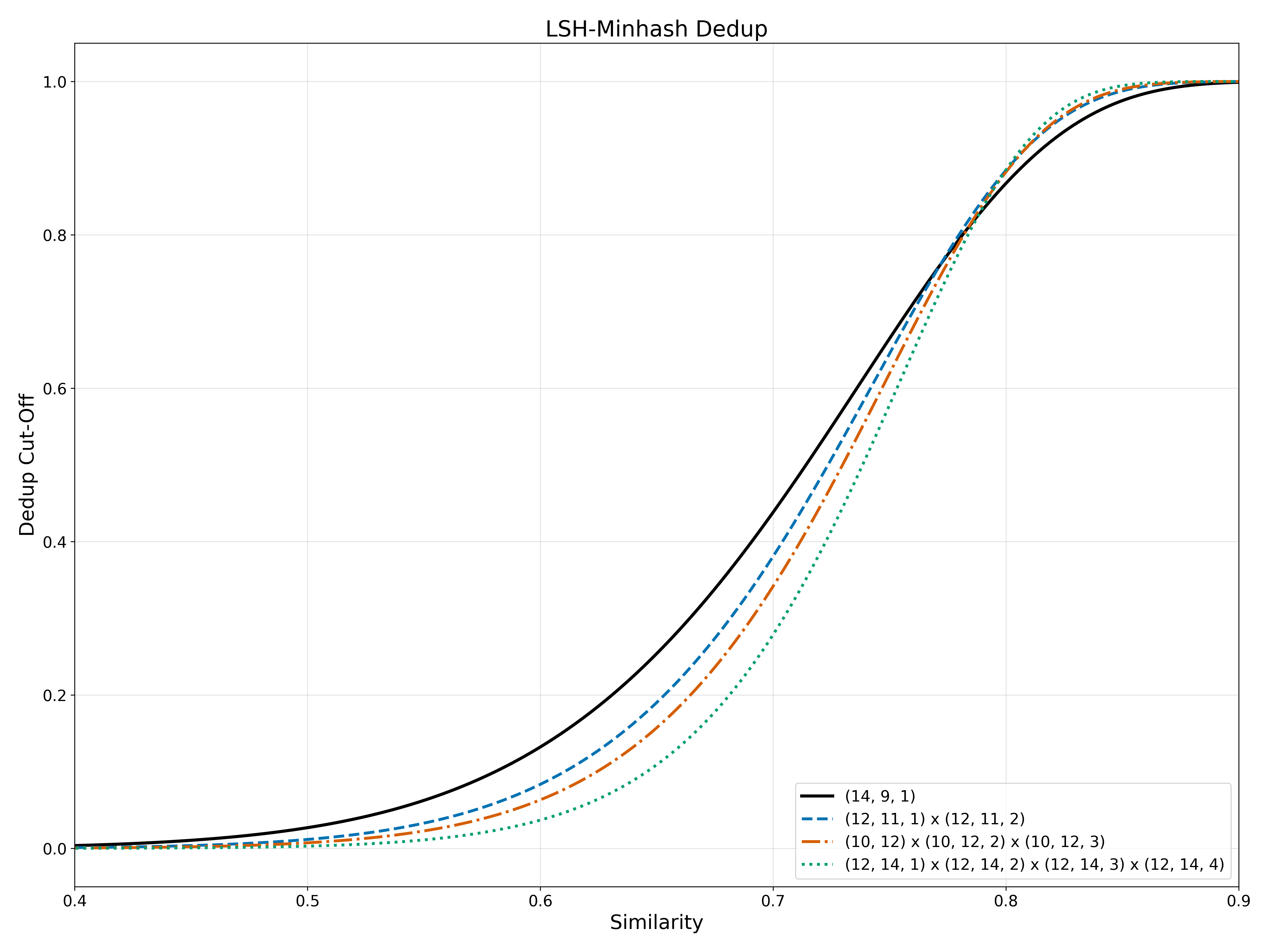
Figure: multi-seed acceptance curves (log scale)
Query-side extension (different task, same design philosophy)
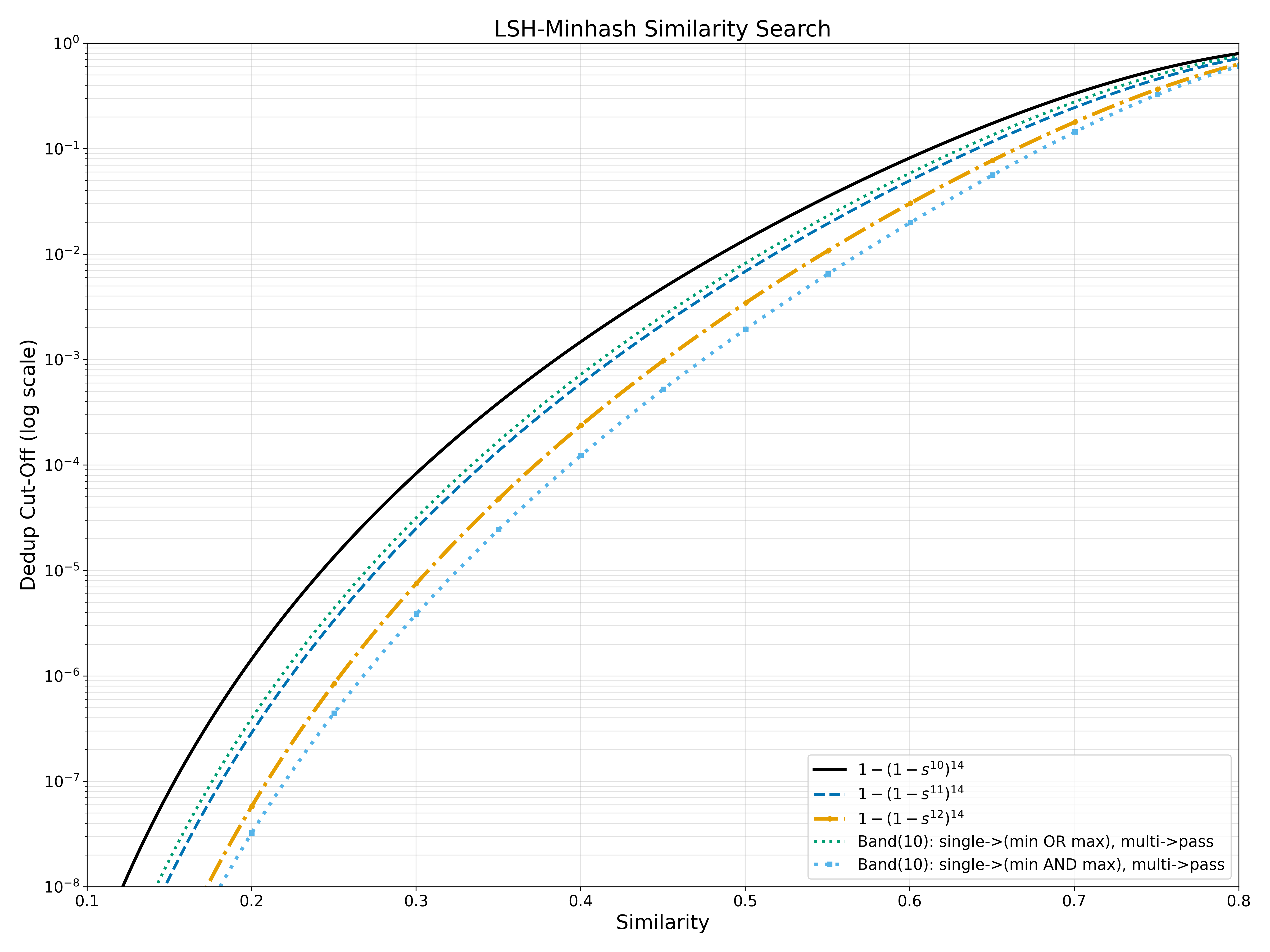
For query-time LSH, there is no global clustering. We only decide whether to accept a candidate.
We evaluate stricter acceptance gates based on:
- single-band + (min OR max) with at-least-two-band fallback
- single-band + (min AND max) with at-least-two-band fallback
These are defined for MinHash-style multi-value signatures. They are not directly applicable to 1-bit SimHash, where each hash contributes only one sign bit and does not expose within-band min/max structure.6
Figure: query probability (linear)
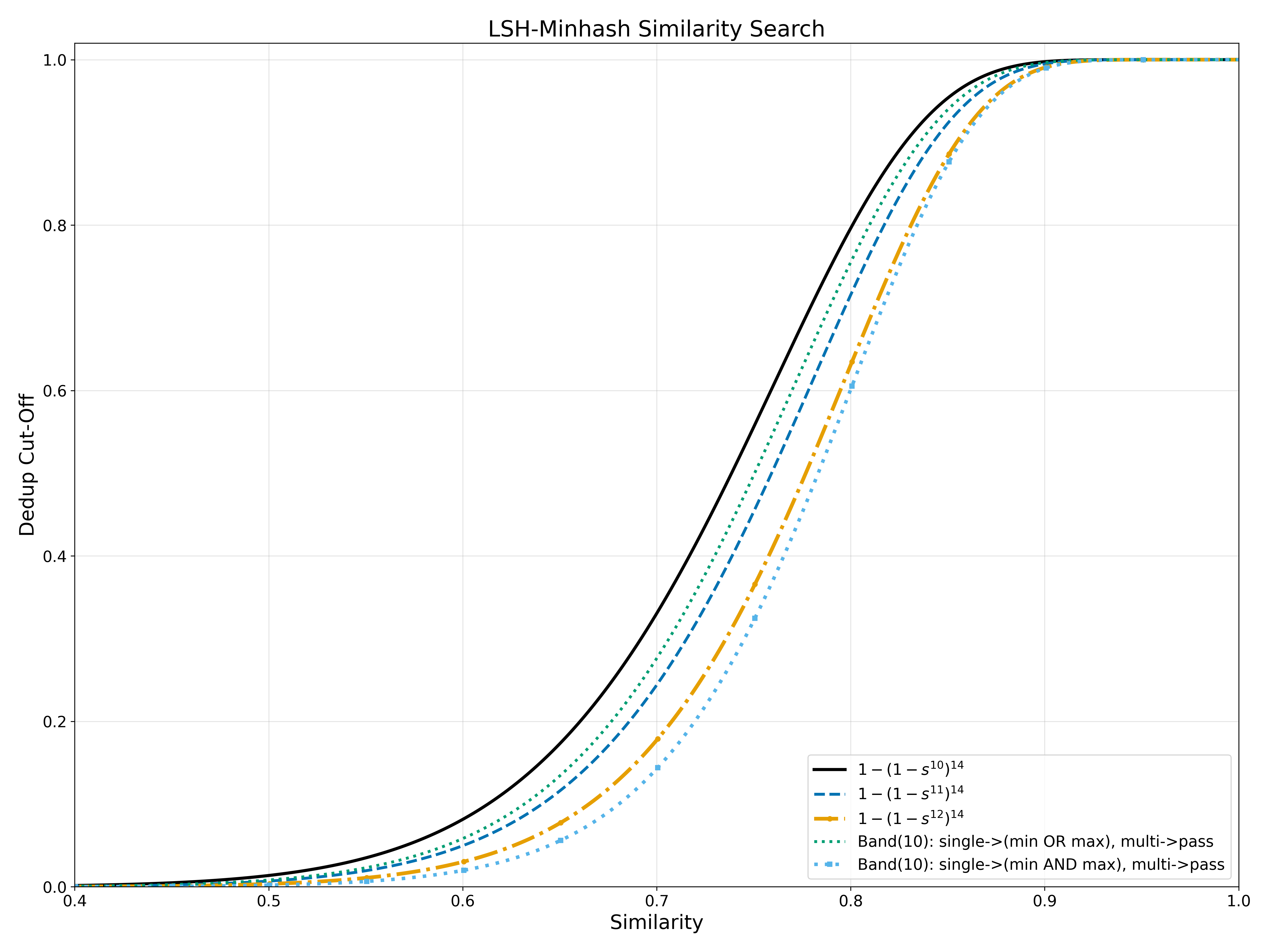
Figure: query probability (log scale)
Case studies at billion scale
Datasets:
- ClueWeb22 subset used in this study: 1.62B docs (from original ~10B after cleaning and non-English filtering).9
- HPLT v2 subset used in this study: 3.98B docs.10
Table 1: headline outcomes
| Corpus | Baseline | Best reported multi-seed setting | Retained docs gain | Max cluster reduction |
|---|---|---|---|---|
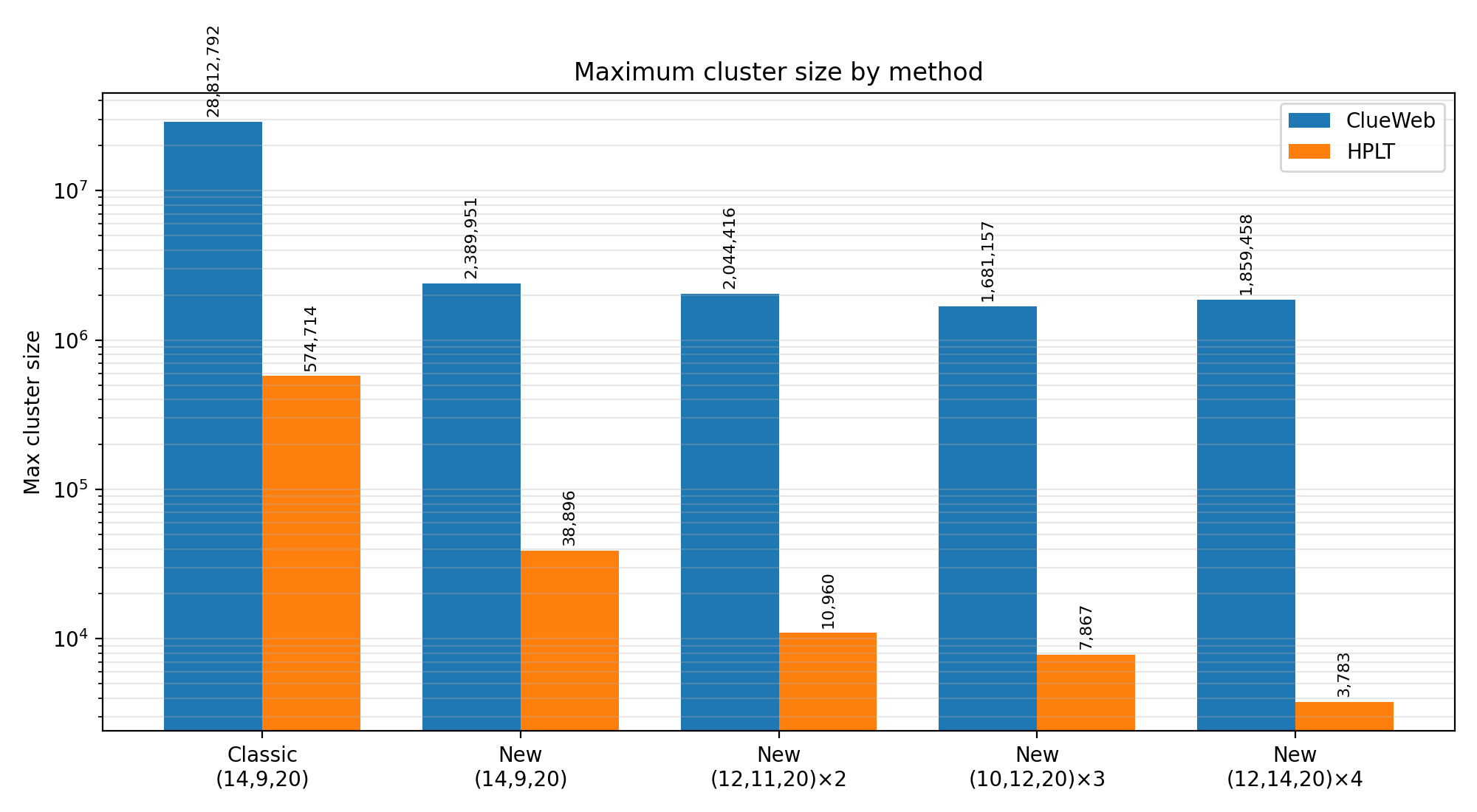
| ClueWeb (1.62B) | 1255M retained, max cluster 28,812,792 | 1319M retained, max cluster 1,859,458 (or 1,681,157 in 3-seed setting) | +64M | ~15.5x to ~17.1x smaller |
| HPLT (3.98B) | 2574M retained, max cluster 574,714 | 2639M retained, max cluster 3,783 | +65M | ~151.9x smaller |
Table 2: near-bound behavior in deeper rounds (tightened bound)
| Corpus | Setting | Round | Greedy / Tight Bound (M) | Ratio |
|---|---|---|---|---|
| ClueWeb | (10,12,20) x 3 | 3 | 14.18 / 14.23 | 99.65% |
| ClueWeb | (12,14,20) x 4 | 4 | 9.250 / 9.263 | 99.86% |
| HPLT | (10,12,20) x 3 | 3 | 26.55 / 26.57 | 99.92% |
| HPLT | (12,14,20) x 4 | 4 | 16.209 / 16.214 | 99.97% |
These deeper-round percentages are the practical signal we care about: the greedy output is frequently extremely close to the tightened incidence bound.
Figure: retained-document fraction
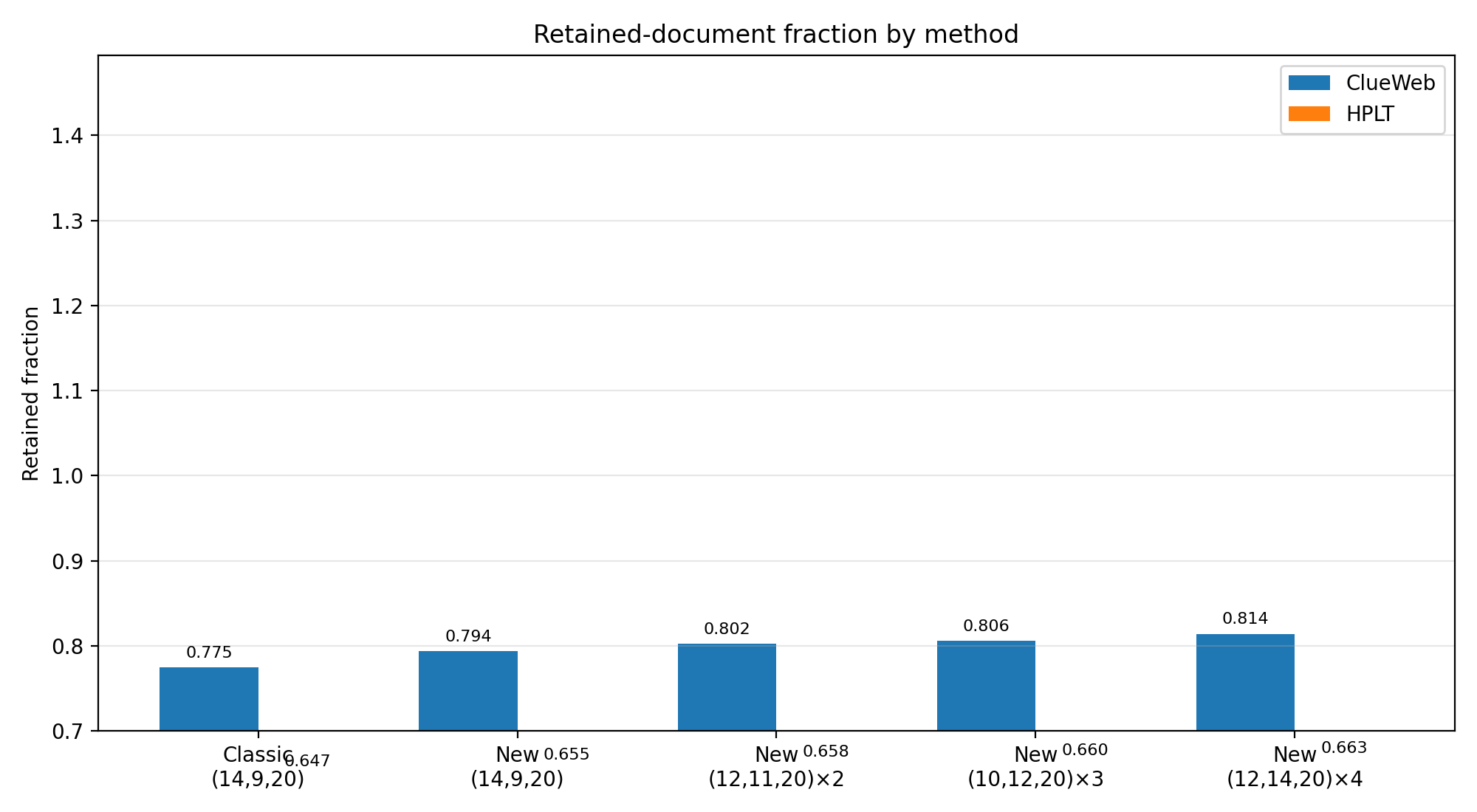
Figure: maximum cluster size (log scale)
Interactive exploration
The interactive panel below lets readers vary $(b,r,T)$ and a min+max proxy coefficient $\kappa$ to inspect curve shape, cutoff steepness, and low-similarity tails.
Why this is deployable, not just theoretical
From an engineering perspective, this proposal is attractive because:
- it changes only stage 3 semantics
- it works directly on emitted bucket files
- it supports rank-aware retention with source-ordered indexing
- multi-seed mode reuses existing process orchestration
In short: same pipeline skeleton, better objective.
Practical migration checklist
If your current dedup stage uses transitive bucket unionization, migration can be done incrementally:
- Keep current signature and bucket generation untouched.
- Deduplicate identical buckets across bands.
- Add weight-1 pre-elimination pass.
- Replace CC merge with bucket-feasible greedy routine.
- Report both loose and tightened bounds for diagnostics.
- Add multi-seed reruns for sharper evidence.
- Track three KPIs each run:
- retained document count
- max cluster size
- greedy/tight-bound percentage by round
Limitations and open directions
Important caveats:
- Hypergraph strong-independent-set remains NP-hard in general.
- Tightened bound is informative but still an upper bound, not exact optimum.
- Query-side min/max gates depend on signature families that expose within-band statistics.
High-value next steps:
- theory under data-realistic heavy-tailed bucket regimes
- end-to-end downstream LLM quality impact under fixed compute
- extension of query gate ideas to additional hash/signature families
Closing
Legacy bucket unionization is a transitive convenience, not the right semantics for multi-band MinHash dedup.
When we replace transitive merging with bucket-feasible strong independence, we get:
- a principled objective,
- explicit structural bounds,
- a scalable stage-3 algorithm,
- and strong empirical gains on billion-document corpora.
If you already run MinHash-LSH dedup at scale, this is a high-leverage place to improve both data efficiency and retained diversity.
Appendix A: notation quick reference
- $V$: document set
- $\mathcal{B}$: deduplicated bucket family (hyperedges)
- $d(v)$: number of incident buckets for document $v$
- $w(B)$: minimum degree among docs in bucket $B$
- $R$: retained root set
- $\phi$: cluster map (doc $\rightarrow$ root)
References
-
Lee et al., “Deduplicating Training Data Makes Language Models Better” (ACL 2022): https://aclanthology.org/2022.acl-long.577/ ↩
-
Penedo et al., “The RefinedWeb Dataset for Falcon LLM” (NeurIPS Datasets and Benchmarks 2023): https://papers.neurips.cc/paper_files/paper/2023/file/fa3ed726cc5073b9c31e3e49a807789c-Paper-Datasets_and_Benchmarks.pdf ↩
-
Together Computer, “RedPajama: an open dataset for training large language models” (NeurIPS Datasets and Benchmarks 2024): https://proceedings.neurips.cc/paper_files/paper/2024/file/d34497330b1fd6530f7afd86d0df9f76-Paper-Datasets_and_Benchmarks_Track.pdf ↩
-
Hugging Face DataTrove repository (pipeline context): https://github.com/huggingface/datatrove ↩
-
Broder, “On the resemblance and containment of documents” (1997): https://doi.org/10.1109/SEQUEN.1997.666900 ↩
-
Charikar, “Similarity estimation techniques from rounding algorithms” (STOC 2002): https://doi.org/10.1145/509907.509965 ↩ ↩2
-
Halldorsson and Losievskaja, “Independent sets in bounded-degree hypergraphs” (2009): https://doi.org/10.1016/j.dam.2008.11.013 ↩
-
Karp, “Reducibility among combinatorial problems” (1972): https://doi.org/10.1007/978-1-4684-2001-2_9 ↩
-
Eickhoff et al., “ClueWeb22” (SIGIR Forum 2022): https://lemurproject.org/clueweb22.php ↩
-
Burchell et al., “An expanded massive multilingual dataset for high-performance language technologies (HPLT)” (2025): https://arxiv.org/abs/2503.10267 ↩
Enjoy Reading This Article?
Here are some more articles you might like to read next: